
By Anthony Dulay, Boeing with Souheil Moghnie, NortonLifeLock and Loren Brent Cobb, Boeing

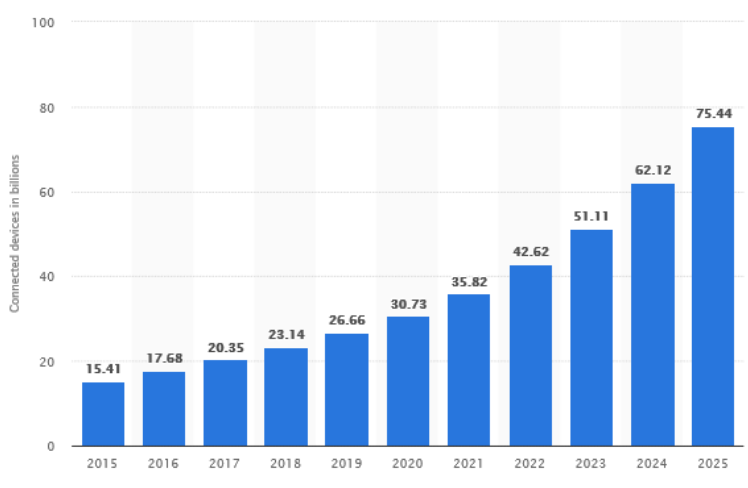
In the digital age, data is everywhere. More people than ever before are using internet-connected, application-centric devices that collect and use some type of data about their users. In fact, according to statista.com there are approximately 75.44 billion devices connected to the internet. Concurrently, we’ve seen the technology behind Big Data mature, taking sophisticated data aggregation and analytics capabilities that used to be only accessible to trained data scientists and putting them into the hands of more people than ever before. As a result, the value of data has risen exponentially.
The implications of this data-driven digital culture on personal privacy are significant. And considering it is all being powered by software, it is fair to wonder how software security practices have evolved to account for privacy protections.
SAFECode has formed a Personal Data Privacy Working Group that will focus on a single, but important, part of this puzzle: what is the role of the software developer in protecting privacy? SAFECode members will be working together to identify and share how their application of secure development practices to the software development lifecycle can improve data privacy, as well as where gaps may exist, or special consideration should be given. We’ll be specifically thinking about unintentional data breaches or those areas where development teams may “shoot themselves in the foot” if they do not give careful consideration to data privacy as software is being built.
The overlapping relationship between security and privacy is simple to understand in theory, yet more difficult to parse in practice. It is fairly clear that data privacy is dependent on good security practices. But we must also recognize that good security practices alone will not guarantee privacy. Rather, data privacy encompasses a number of security and technology disciplines and an understanding of legal and cultural drivers.
Privacy and data protection rules are inevitably influenced by legal traditions, cultural and social values, and technological developments, all of which tend to vary from one part of the world to the next. Given the current legal climate around personal data privacy, and resulting compliance mandates, software developers tend to be familiar with the need to carefully consider how they collect and store Personally Identifiable Information (PII), which is any information that can be used to identify a specific person, such as date of birth, personal IP address, social security numbers, etc. Arguably, most mature software companies have security measures in place to protect many types of PII.

However, as our ability to isolate, collect and use data has grown, so too has the value of data not traditionally considered PII, such as passwords, geo-location or even application usage statistics. This “non-PII data” is often at higher risk of slipping through the cracks of privacy and security policies. Further, the aggregate of non-PII could be PII. Pieces of seemingly less important – or at least not private – data can be constructed or reconstructed to create new data that does compromise privacy or at minimum run afoul of confidentiality agreements. As a result, someone with malicious intent could gather, compile, and sell bits of information in composite form, based on what customers are sharing to third-party providers.
Privacy measures should be baked into software as early as possible in the development life cycle. As a developer, you may think that the data you’re collecting is anonymized or not private or important, and that might be the case; however, you need to keep in mind that the aggregate of anonymous data can leak some sensitive information, leading to intentional or unintentional misuse. The primary consideration for developers should be: can my service, software, or data be utilized beyond its original intended purpose and will that put user privacy at risk? And, if so, can better security practices, such as inclusion of anonymization algorithms, be applied to protect against misuse?
Over the next few months, SAFECode’s Personal Data Privacy Working Group will be meeting to discuss and share best practices around privacy-related software security challenges. We will start by discussing what mechanisms or strategies a software provider can leverage to assure needed data is gathered, but also protected and expired properly. Developers must thoughtfully consider what user data they should collect and what data they should keep, share, or discard. For instance, how can they assure that no tangible forensic user data remains in cache, in logs, in cookies, or in provider-side systems? What happens when the developer is faced with the choice between making the data useable but identifiable or making the data unusable but not identifiable. How do we balance business needs with privacy imperatives?
Keep an eye on the SAFECode blog to learn more. If you are a SAFECode member interested in joining this effort, please contact our Member Helpdesk to sign up.